
Related Questions:
– What is Gradient Boosting (GBM)?
– What is a Random Forest?
– GBM vs Random Forest: which algorithm should be used when?
Gradient Boosting Machines and Random Forest are both popular tree-based machine learning algorithms used for supervised learning tasks such as classification and regression. However, they differ in several key ways as shown below:
[table id=12 /]
As shown in the above table, both GBM and Random Forest are ensemble methods, however, they differ in their training process, computational resources, model results, and interpretability. The choice between GBM and Random Forest depends on the specific characteristics of the dataset, the modeling objectives, model performance, and the available computing resources. It is usually advisable to try as many algorithms as possible and even consider an ensemble of multiple algorithms before making the final decision.
Illustrative example: Comparing performance of Gradient Boosting and Random Forest for a Cancer study
The following graph taken from the book ‘An Introduction to Statistical Learning’ is an illustrative example of performance of Boosting algorithms vs Random Forest trained on Gene expression data to predict cancer (binary classification problem) (lower classification error is better).
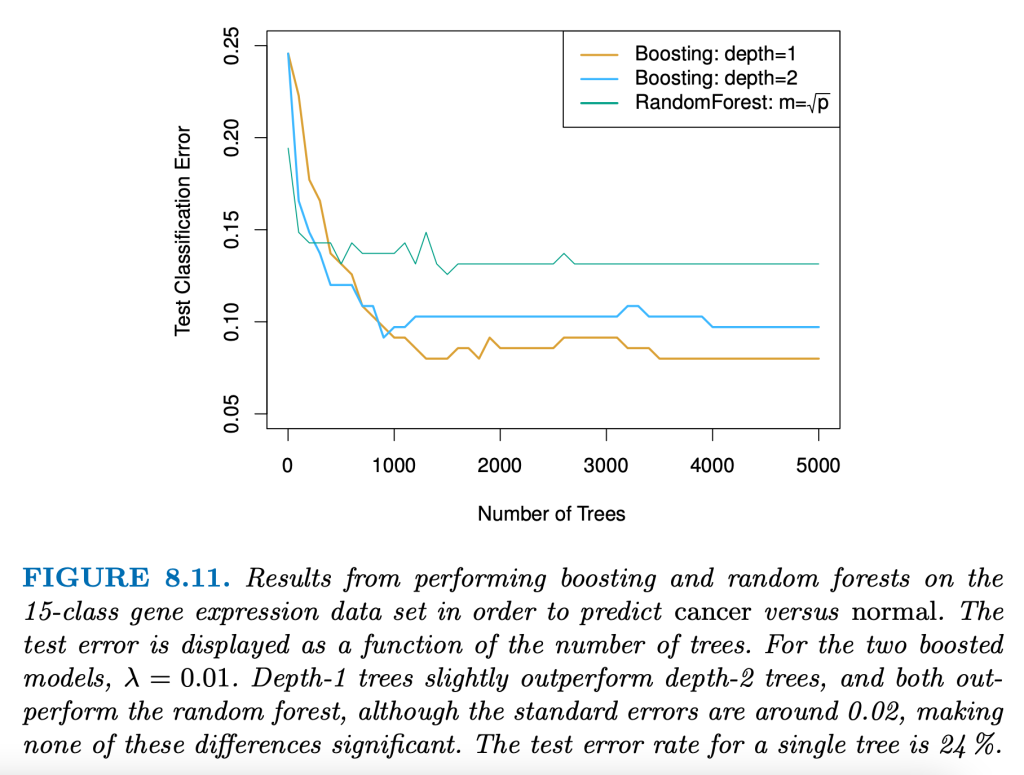
Note: This example is for illustration purposes only. The performance of different models can vary based on training data and modelling process
Video Explanation
- In the following video, Josh Stramer takes viewers on a StatQuest that motivates Boosting, and compares and contrasts it with Random Forest. Even though the video is titled “Adaboost”, it does explain the differences between Random Forest and Boosting.
