
Related Questions:
– What is Bag-of-Words Model?
– What is Natural Language Processing (NLP) ? List the different types of NLP tasks
About Topic Modeling
Source: OpenGenus
Topic modeling is a machine learning technique used in text analysis to discover underlying topics or themes within a collection of documents. It is an unsupervised learning method, which means it does not require pre-labeled data or training. Instead, it employs statistical algorithms to uncover hidden patterns and relationships between words in the text, thereby identifying clusters of words that represent topics. By identifying the underlying topics in a collection of documents, topic modeling can help organize and make sense of large amounts of textual data.
Topic modeling has emerged as a highly useful technique in Natural Language Processing (NLP) for deriving meaningful insights from unstructured textual data. Example of such data includes articles, blog posts, customer reviews, emails, and social media posts.
Algorithms used for Topic Modeling
- Latent Dirichlet Allocation (LDA)
LDA is one of the most widely used topic modeling algorithms. It assumes that every document is a distribution of topics and every topic is a distribution of words. It iteratively assigns words to topics and documents to topics in a way that optimally explains the observed word-document relationships. Through this process, LDA extracts a set of topics and the distribution of words within each topic.
In LDA, all the documents in the collection share the same set of topics, but each document exhibits those topics with different proportion.
Infographic explaining Latent Dirichlet Allocation (LDA)
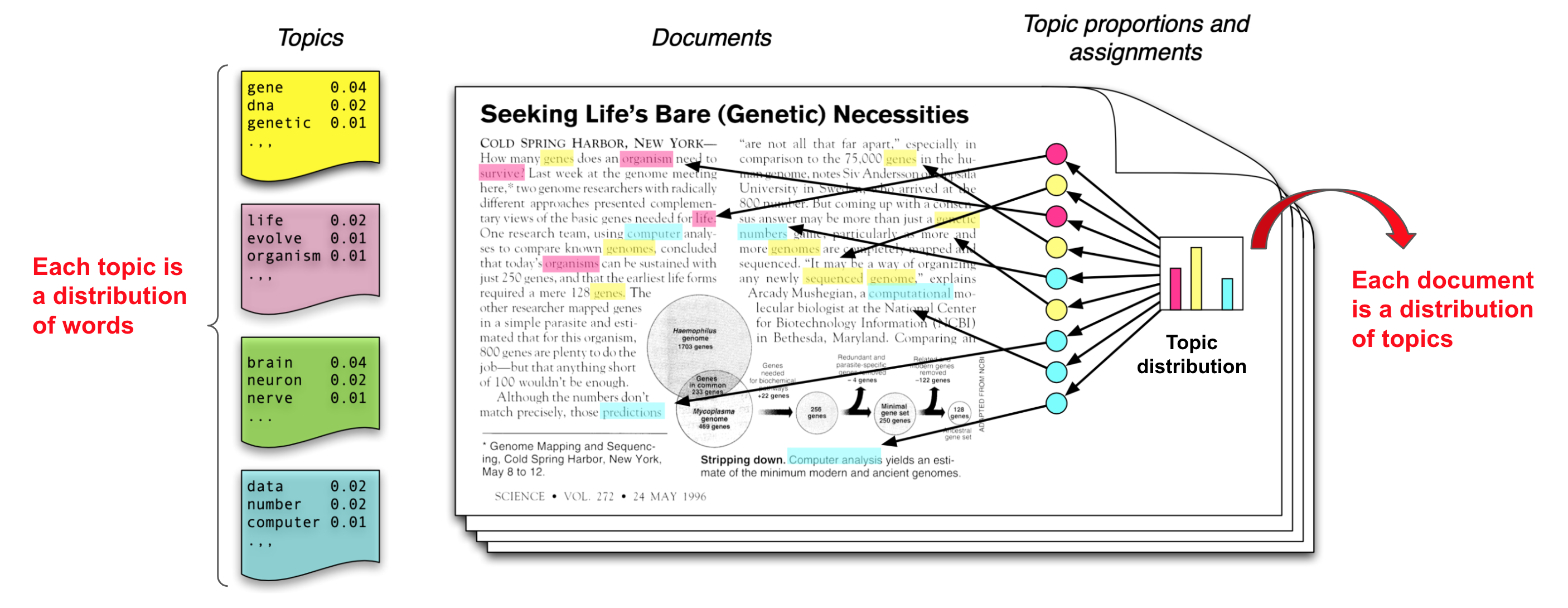
It assume that some number of “topics,” which are distributions over words, exist for the whole collection (far left). To identify topic distribution of each document, first choose a distribution over the topics (the histogram at right); then, for each word, choose a topic assignment (the colored coins) using statistical analysis
Source: Introduction to Probabilistic Topic Models paper by Blei et. al
Variants of LDA: Hierarchical Dirichlet Process (HDP), Correlated Topic Model (CTM), Dynamic Topic Models (DTM), Structural Topic Model (STM)
- Latent Semantic Analysis (LSA)
LSA, also known as Latent Semantic Indexing (LSI), applies singular value decomposition (SVD) to a term-document matrix to capture the underlying semantic structure in text data.
Variants of LSA: Probabilistic Latent Semantic Analysis (pLSA)
- Non-Negative Matrix Factorization (NMF)
NMF factorizes the term-document matrix into two lower-dimensional matrices, one representing topics and the other representing document-topic weights. It enforces non-negativity constraints.
- Word Embedding-Based Models
Some models, like Word2Vec and Doc2Vec, use word embeddings to capture semantic relationships between words and documents. These embeddings can be used for topic modeling by clustering words or documents in embedding space.
- BERTopic: BERTopic is a topic modeling technique that utilizes pre-trained BERT embeddings and clustering algorithms to discover topics in text data. It leverages the power of transformer-based language models.
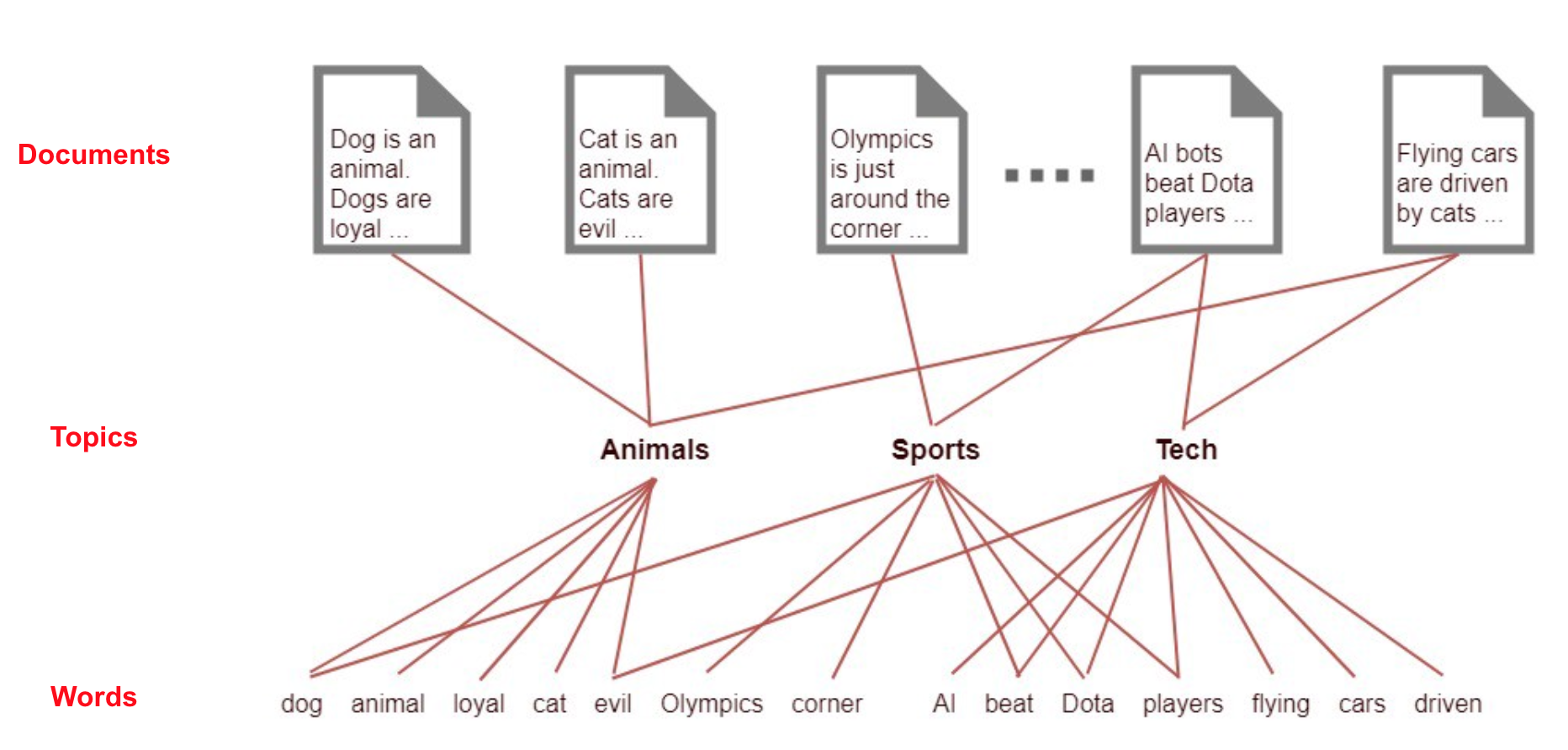
How Topic Modeling works?

![]()

![]()

![]()

![]()

Real world applications of Topic Modeling
Some common applications of topic modeling is depicted in the following table:
[table id=16 /]
Advantages and Disadvantages of Topic Modeling
[table id=17 /]
Video Explanation
- The first half of the video provides a clear explanation of the concept of topic modeling using a practical example. The second half of the video demonstrates the implementation of the LDA model for topic modeling in Python within a Jupyter notebook (Total Runtime: 25 mins)
Source: A Dash of Data
